A Generative AI agent can be defined as an application that attempts to achieve a goal by observing the world and acting upon it using the tools that it has at its disposal.
Agents are autonomous and can act independently of human intervention, especially when provided with proper goals or objectives they are meant to achieve. Agents can also be proactive in their approach to reaching their goals. Even in the absence of explicit instruction sets from a human, an agent can reason about what it should do next to achieve its ultimate goal.
Architecture
An agent is composed of three components:
- the model
- the tools
- the orchestration layer
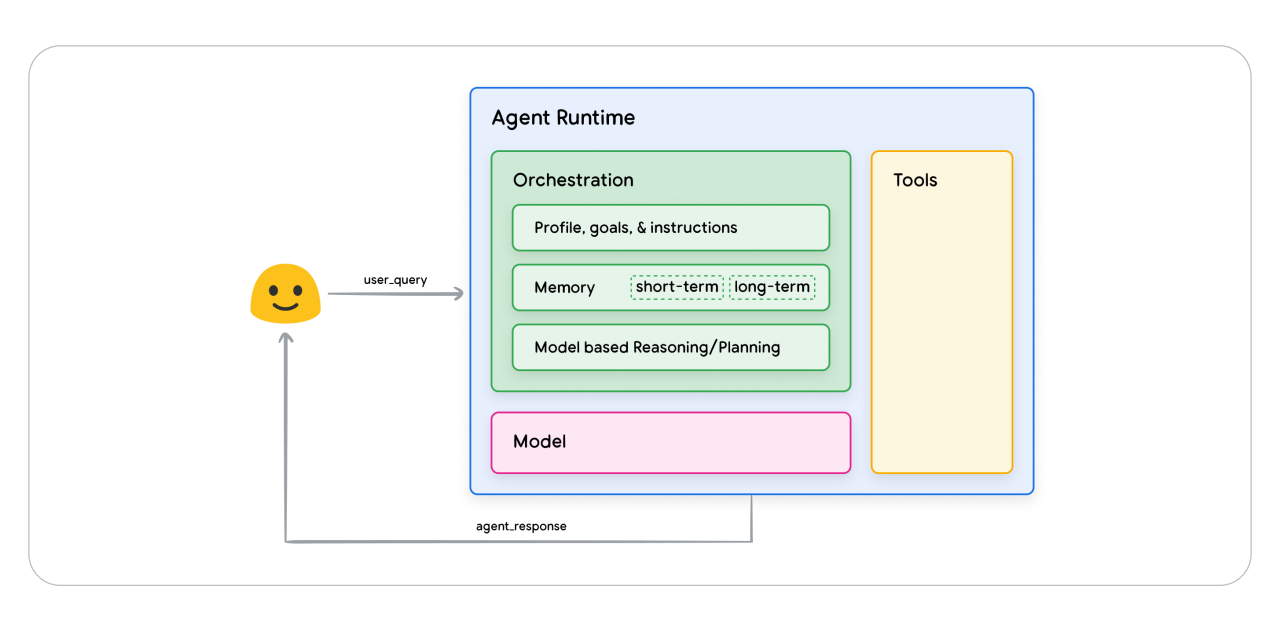
The Model
In the scope of an agent, a model is the language model (LM) that will be utilized as the centralized decision maker for agent processes. The model used by an agent can be one or multiple LM’s of any size (small / large) that are capable of following instruction based reasoning and logic frameworks, like ReAct, Chain-of-Thought, or Tree-of-Thoughts.
Models can be general purpose, multimodal or fine-tuned based on the needs of your specific agent architecture and are not trained with specific configuration settings but their performance can be refined by providing it with examples that showcase the agent’s capabilities, including instances of the agent using specific tools or reasoning steps in various contexts.
The tools
Foundational models, despite their impressive text and image generation, remain constrained by their inability to interact with the outside world. Tools bridge this gap, empowering agents to interact with external data and services while unlocking a wider range of actions beyond that of the underlying model alone.
Tools have different names, Google uses extensions, functions and data stores
Extensions
An Extension bridges the gap between an agent and an API by:
- Teaching the agent how to use the API endpoint using examples.
- Teaching the agent what arguments or parameters are needed to successfully call the API endpoint
Extensions can be crafted independently of the agent, but should be provided as part of the agent’s configuration. The agent uses the model and built-in examples at run time to decide which Extension, if any, would be suitable for solving the user’s query.
Functions
Functions are similar to extension with one notable difference, that they are executed on the client-side and the agent doesn’t make direct API call. Fundamentally, the agent returns the function to be invoked and the parameter, but the actual invocation is done somewhere else in the application stack.
This can be useful for example if the application needs human intervention, batching requests, for extra security consideration, etc.

Data stores
Data Stores allow developers to provide additional data in its original format to an agent, eliminating the need for time-consuming data transformations, model retraining, or fine- tuning.
The Data Store converts the incoming document into a set of vector database embeddings that the agent can use to extract the information it needs to supplement its next action or response to the user.
Orchestration layer
The orchestration layer describes a cyclical process that governs how the agent takes in information, performs some internal reasoning, and uses that reasoning to inform its next action or decision. In general, this loop will continue until an agent has reached its goal or a stopping point. The complexity of the orchestration layer can vary greatly depending on the agent and task it’s performing.
The orchestration layer uses the rapidly evolving field of prompt engineering and associated frameworks to guide reasoning and planning, enabling the agent to interact more effectively with its environment and complete tasks. Research in the area of prompt engineering frameworks and task planning for language models is rapidly evolving, yielding a variety of promising approaches. Common frameworks and reasoning techniques include ReAct, CoT, ToT
Chosing the right tool
General training helps models develop the skill they need to choose the right tool, but real-world scenarios often require knowledge beyond the training data. To help the model gain access to this type of specific knowledge, several approaches exist: • In-context learning: This method provides a generalized model with a prompt, tools, and few-shot examples at inference time which allows it to learn ‘on the fly’ how and when to use those tools for a specific task. The ReAct framework is an example of this approach in natural language. • Retrieval-based in-context learning: This technique dynamically populates the model prompt with the most relevant information, tools, and associated examples by retrieving them from external memory. • Fine-tuning based learning: This method involves training a model using a larger dataset of specific examples prior to inference. This helps the model understand when and how to apply certain tools prior to receiving any user queries.
Agents versus models
Agents are fundamentally different than models from many perspectives:
- Knowledge: models knowledge is limited to what is available in their training data, while agents knowledge is extended via tools
- Session history: models perform a single inference-prediction while agents save session history
- Logic layer: users can prompt using reasoning frameworks such as (CoT, ReAct, etc) but these are not built-in in the system