Self-attention is a crucial mechanism in transformers; it enables them to focus on specific parts of the input sequence relevant to the task at hand and to capture long-range dependencies within sequences more effectively than traditional RNNs.
Self-attention helps to determine the relationships between different words in a text.
In recommender systems, the same mechanism can operate over activity or candidate sequences rather than words. A ranker can let a candidate Pin attend to a user’s recent saved Pins, clicked Pins, searches, or board context. See Recommendation Ranking Models for where attention sits after categorical embedding lookups.
Example
For example, in the sentence “The tiger jumped out of a tree to get a drink because it was thirsty” , tiger and it are the same object so they should be strnogly connected
How attention works
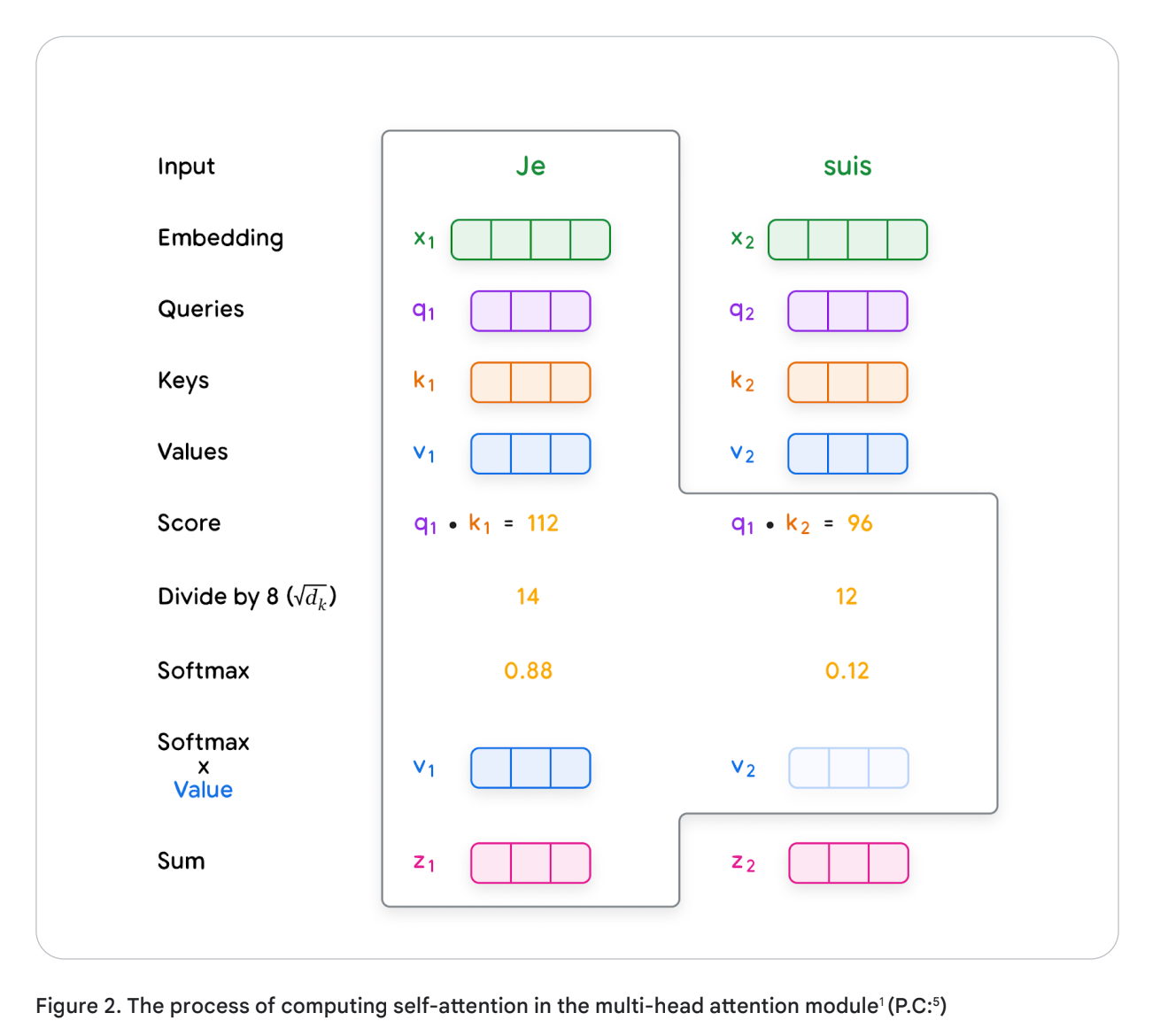
Self-attention works through multiple steps:
- Creating queries, keys, and values: Each input embedding is multiplied by three learned weight matrices (Wq, Wk, Wv) to generate query (Q), key (K), and value (V) vectors. These are like specialized representations of each word. • Query: The query vector helps the model ask, “Which other words in the sequence are relevant to me?” • Key: The key vector is like a label that helps the model identify how a word might be relevant to other words in the sequence. • Value: The value vector holds the actual word content information.
- Calculating scores: Scores are calculated to determine how much each word should ‘attend’ to other words. This is done by taking the dot product of the query vector of one word with the key vectors of all the words in the sequence.
- Normalization: The scores are divided by the square root of the key vector dimension (dk) for stability, then passed through a softmax function to obtain attention weights. These weights indicate how strongly each word is connected to the others.
- Weighted values: Each value vector is multiplied by its corresponding attention weight.
The results are summed up, producing a context-aware representation for each word.
Tip
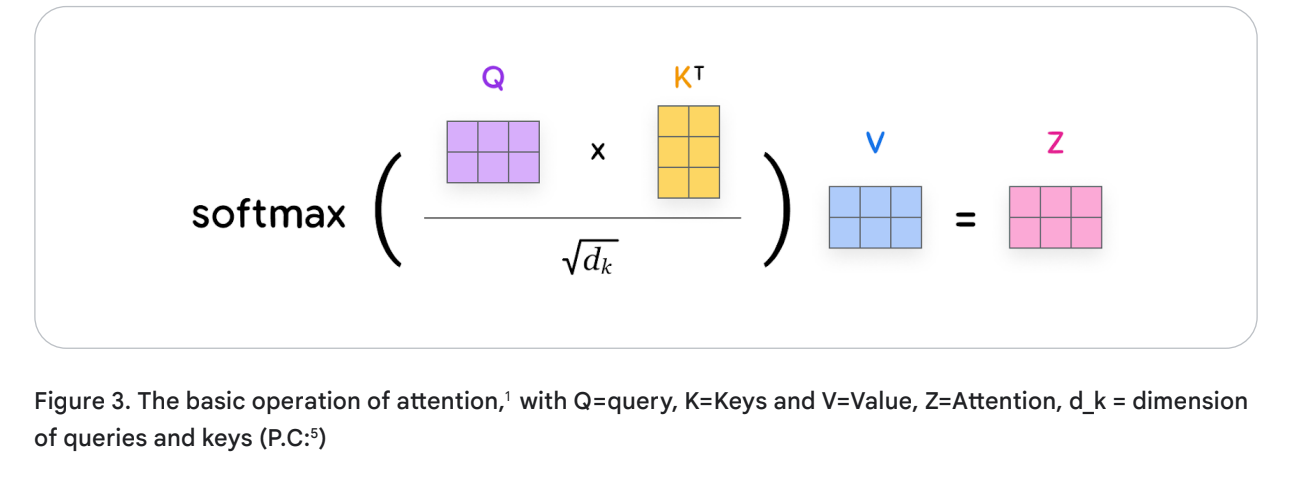
In practice, the computation of attention is done in parallel using matrix multiplication
Multi-head attention
Multi-head attention employs multiple sets of Q, K, V weight matrices. These run in parallel, each ‘head’ potentially focusing on different aspects of the input relationships. The outputs from each head are concatenated and linearly transformed, giving the model a richer representation of the input sequence.
The use of multi-head attention improves the model’s ability to handle complex language patterns and long-range dependencies. This is crucial for tasks that require a nuanced understanding of language structure and content, such as machine translation, text summarization, and question-answering. The mechanism enables the transformer to consider multiple interpretations and representations of the input, which enhances its performance on these tasks.
Attention in Decoder-Only vs. Encoder-Decoder Models
In decoder-only models (like GPT), attention works differently during auto-regressive generation: each newly generated token requires an updated query vector (Q) to capture the evolving context of the sequence so far. However, key (K) and value (V) vectors for the initial input (prompt) are computed once, cached, and reused, reducing the need to recompute them at each step. This contrasts with encoder-decoder models (e.g., BERT or translation transformers), where the encoder computes Q, K, and V vectors for the entire input sequence once, and the decoder processes the output sequence in its entirety. During generation, the encoder provides the decoder with fixed K and V vectors, allowing the decoder to query this encoded information without requiring updates to K and V with each new token.
Why Auto-Regressive Attention is Simpler
Auto-regressive attention in decoder-only models may appear repetitive, but it simplifies training and generation by focusing only on predicting the next token based on previously generated tokens. This left-to-right, token-by-token prediction aligns with real-world text generation and maintains computational efficiency by caching K and V. The repeated Q updates are computationally lighter than recalculating K and V each time, making the model faster while generating coherent sequences.