The role of a scheduler is to schedule work, i.e. assigning CPU time(a global resource) to units of work, commonly called tasks. Tasks are independent and any number of runnable tasks can execute concurrently.
Single queue, single processor
At the most basic level, the scheduler can be modeled as a run queue and a processor that drains the queue.
while let Some(task) = self.queue.pop() {
task.run();
}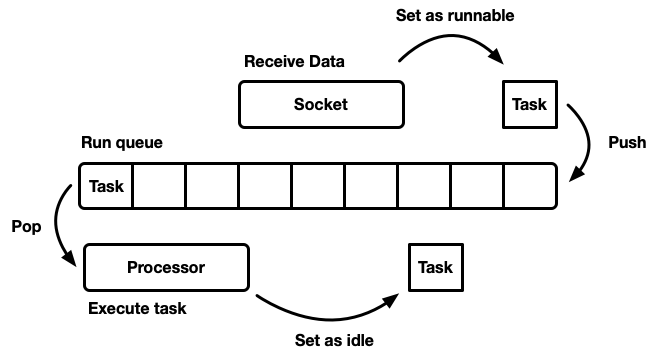
The approach above is a single queue, single processor and would end up in using a single thread only, which is not acceptable in modern CPU.
Single queue, multi-processor
A first alternative could be using a single queue with multiple processors
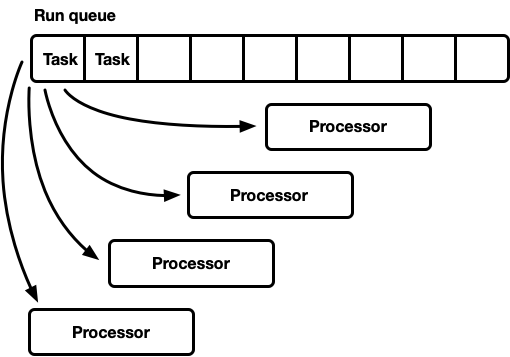
Commonly the algorithm is an intrusive linked list to allow allocations for push and pop. Concurrent access from producers(push) is typically handled in a lock-free way using atomic compare and swap with appropriate usage of the memory ordering guarantees. Popping requires a mutex to coordinate consumers
Tip
It is possibly to implement lock-free multi-consumer queue but the overhead needed to correctly avoid locks is greater than just using the mutex
Tip
Single queue multi processors schedulers are commonly used to implement thread-pools because they are simple to implement and they are fair or first-in, first-out.
Important
Fairness is not always a desirable property of scheduling, when we are parallelizing a computation the only important factor is how fast the result is computed, and not the fairness of each individual subtask
Concurrency, contention and mechanical sympathy
The single queue approach works well for general-purpose thread pools, but when the tasks are very fast, the overhead from contending on the queue to pop a new task is significant.
Important
This is because accessing the tail concurrently from multiple threads requires cross-thread synchronization that is expensive: instead of reading a new task from the L1 cache(1-4ns), each time a core pops a task, the specific core caches are invalidated by the cache coherence protocol and each core needs to read from the main memory/DRAM that has a latency of 100-200 ns
Note
Some architectures have an L2 cache shared across core that can alleviate the problem since it has access time in 10-20ns
Many processors, each with their own queue
Using multiple single-threaded schedulers where each processor gets its own run queue and tasks are pinned to a specific processor avoids the problem of synchronization entirely. It remains necessary to support thread-safe push operations since any thread can place new work on the queue, or using a separate thread-safe queue and unsafe queue and move internally the nodes.
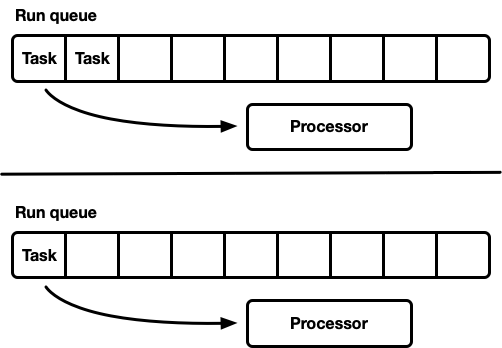
Unless workload is entirely uniform this model leads to some processor becoming idle while others are under load, and is therefore not used by general purpose schedulers(although it is used in Seastar - Seastar)
Work stealing
Work-stealing schedulers are based on the same idea of the “queue per processor” scheduler, but it address under utilization allowing processors to check sibling queues and steal from them
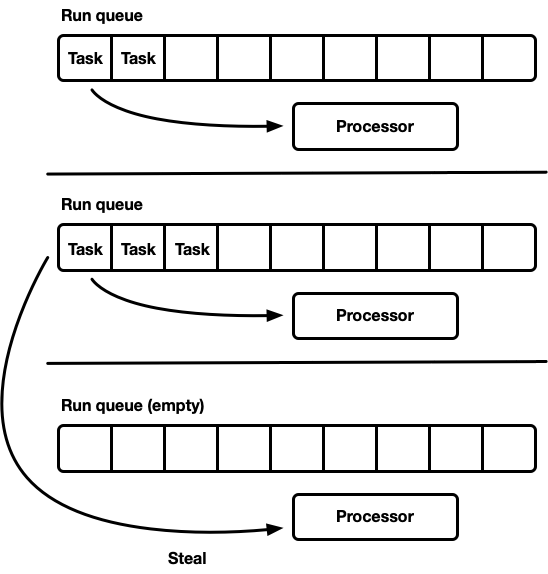
Note
This algorithm is more complicated, since the stealing operation needs to b implemented and if done wrongly its benefits are lost.