The Log-Structured Merge-Tree (LSM) is a write-optimized data structure designed to handle high-throughput workloads by batching writes, organizing data hierarchically across levels, and periodically compacting on-disk data.
Core Components and Workflow
Write Path
- MemTable: All writes are initially buffered in a sorted in-memory structure, such as a skiplist or red-black tree. This allows for fast writes and immediate organization by key.
- Write-Ahead Log (WAL): Each write is also appended to a sequential, append-only log on disk for durability. In case of a crash, the WAL is replayed to restore the MemTable.
- Flushing to SSTables: When the MemTable reaches its size limit, it is flushed to disk as an immutable Sorted String Table (SSTable). SSTables are:
- Sorted key-value pairs serialized in a compact, sequential format.
- Accompanied by metadata like key ranges, an index block, and a Bloom filter.
Read Path
- Lookups start in the MemTable to check for recent writes.
- If not found, the query proceeds to SSTables, starting with Level 0, which contains the most recent and overlapping files.
- Metadata optimizations:
- The global index identifies which SSTables might contain the key.
- Bloom filters reduce unnecessary file reads by probabilistically checking key existence.
- The SSTable’s index block maps keys to offsets for binary search. If a key exists in multiple SSTables, the version in the most recent level is used.
Levels in LSM Trees
Levels organize SSTables hierarchically to balance query performance and storage efficiency.
- Level 0 (L0):
- Contains newly flushed SSTables, often with overlapping key ranges.
- Requires querying all relevant files for key lookups.
- Deeper Levels (L1, L2, …):
- SSTables are larger and do not overlap in key ranges within a level.
- Each level typically grows exponentially in size (e.g., Level 1 may hold 10x more data than L0, Level 2 may hold 10x more than L1). As SSTables move to deeper levels through compaction, they are merged into larger, non-overlapping files, improving read efficiency.
Tip
In LSM, overlapping keys in Level 0 (L0) occur because SSTables at this level are direct dumps of the MemTable. When the MemTable is flushed to disk, the resulting SSTable is written as-is, without merging or deduplication. This avoids the overhead of compaction at every flush, ensuring high write throughput. Compaction from Level 0 to Level 1 is mandatory to resolve these overlaps, as Level 1 and beyond enforce strict non-overlapping key ranges within each level.
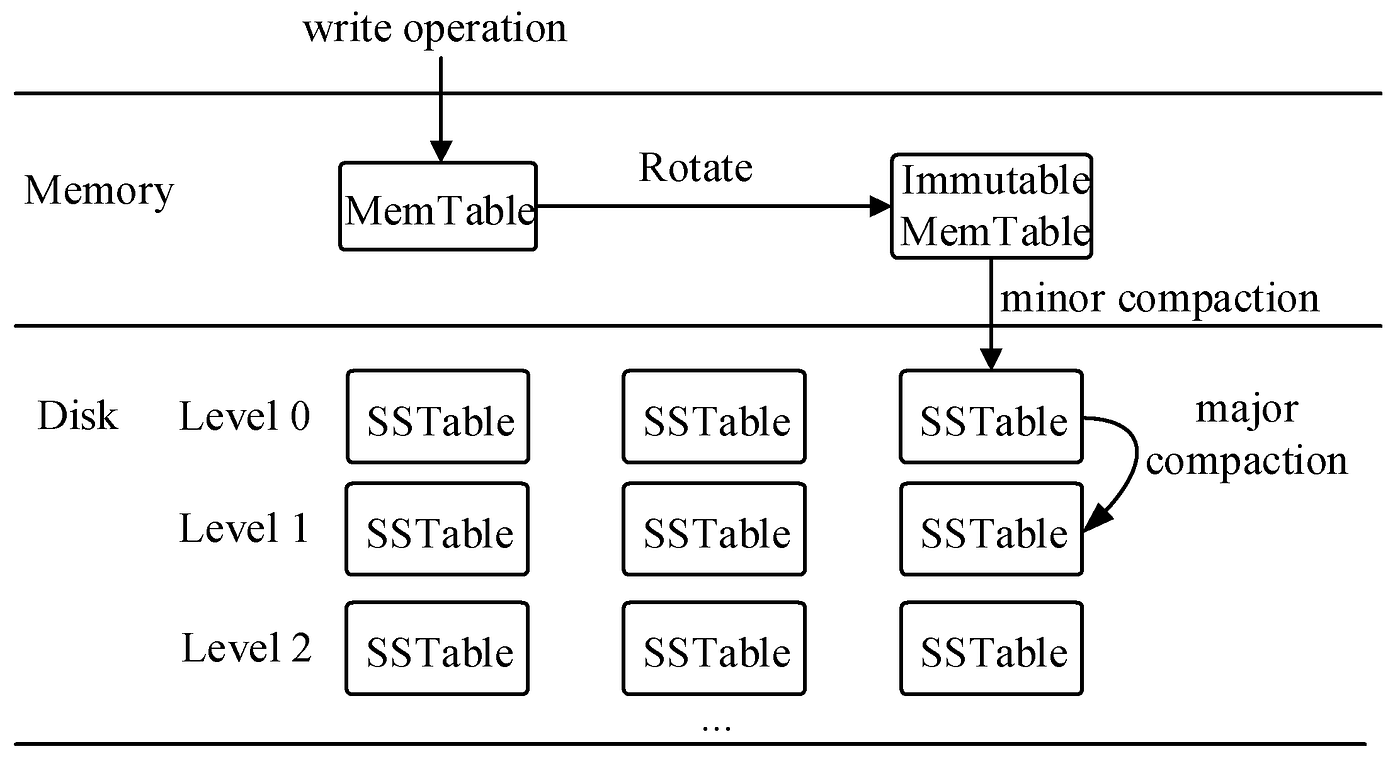
Compaction
Compaction periodically merges SSTables within or across levels to maintain efficiency. It:
- Eliminates stale data (e.g., older versions of keys or deleted keys).
- Consolidates overlapping files into larger, sorted SSTables.
- Reduces read amplification by minimizing the number of files scanned for a query. Strategies for compaction include:
- Size-Tiered Compaction: Merges smaller SSTables when they reach a threshold.
- Level-Based Compaction: Ensures non-overlapping key ranges within each level. While compaction improves query performance, it introduces write amplification as data is rewritten multiple times across levels.
Metadata and Crash Recovery
Metadata ensures efficient querying and durability:
- Global Manifest:
- Tracks all SSTables, their levels, key ranges, and timestamps.
- Persisted on disk and reloaded into memory on restart to rebuild indexes.
- Per-SSTable Metadata:
- Key ranges: Helps locate relevant files for queries.
- Bloom filters: Enable quick checks for key existence.
- Index block: Maps keys to byte offsets in the SSTable for fast binary search. Crash recovery relies on replaying the WAL to restore the MemTable and leveraging the global manifest to rebuild SSTable tracking.
Evolution and Major Projects
The LSM design, introduced in 1996 by Patrick O’Neil et al., gained widespread adoption through innovations in subsequent projects:
- 2006: Bigtable:
- Google popularized LSM concepts with SSTables and hierarchical levels.
- 2011: LevelDB:
- Brought a high-performance embedded LSM implementation, widely adopted for its simplicity and efficiency.
- 2013: RocksDB:
- Extended LevelDB with enterprise-level features, including tunable compaction and optimizations for SSDs.
- Apache Cassandra:
- Leveraged LSM for distributed, write-heavy NoSQL workloads.
- ScyllaDB and TiKV:
- Modern distributed databases optimized for high-throughput, write-intensive use cases.
Why LSM Differs from Tree Structures
Traditional on-disk trees, like B-Trees, update data in-place, requiring random I/O and rebalancing. In contrast:
- LSM defers on-disk organization, batching writes in memory and appending sorted data sequentially to disk.
- SSTables avoid pointer-based structures, using flat serialized files for efficiency.
- Compaction replaces rebalancing, reducing the need for complex update mechanisms on disk.
See also
- LSM Compaction — write amplification, leveled vs. size-tiered compaction, and time-based partitioning
- BTrees — the alternative approach: in-place updates with B-tree rebalancing
- VictoriaMetrics — a TSDB that uses monthly-partitioned LSM trees to bound write amplification