Arrow is a collection of libraries and specifications that make it easy to build high-performance software utilities for processing and transporting large datasets. It was co-created by Jacques Nadeau and Wes McKinney, the creator of pandas, and first released in 2016.
While Apache Parquet is an on-disk columnar file format, Arrow is an in-memory format, which targets processing efficiency, with numerous tactics such as cache locality and vectorization of computation.
Lingua Franca of data analytics
Different databases, programming languages, and libraries tend to implement and use separate internal formats for managing data, which means that any time you’re moving data between these components for different uses, you’re paying a cost to serialize and deserialize that data every time, up to 90%. Not only that but lots of time and resources get spent reimplementing common algorithms and processing in those different data formats over and over. If we can standardize on an efficient, feature-rich internal data format that can be widely adopted and used instead, this excess computation and development time is no longer necessary.
Key Strengths
The Arrow libraries provide mechanisms to directly share memory buffers to reduce copying between processes by using the same internal representation, regardless of the language. This is what’s being referred to whenever you see the term zero-copy.
By adopting a columnar format that keeps column data contiguous in memory, Arrow allows the operations to be vectorized, taking advantage of the SIMD capability of modern processors. Such a characteristics also works well with GPUs
Physical memory layout
The Arrow columnar format specification includes definitions of the in-memory data structures, metadata serialization, and protocols for data transportation. The format itself has a few key promises:
- Data adjacency for sequential access
- O(1) (constant time) random access
- SIMD and vectorization-friendly
- Relocatable, allowing for zero-copy access in shared memory
An array or vector is defined by the following information:
- A data type (typically identified by an enum value and metadata, see Glossary)
- A group of buffers
- A length as a 64-bit signed integer
- A null count as a 64-bit signed integer
- Optionally, a dictionary for dictionary-encoded arrays (more on these later in this chapter)
Nested array type
To define a nested array type, there would also be one or more sets of this information that would then be the child arrays. Arrow defines a series of data types and each one has a well-defined physical layout in the specification.
Quick summary of physical layouts
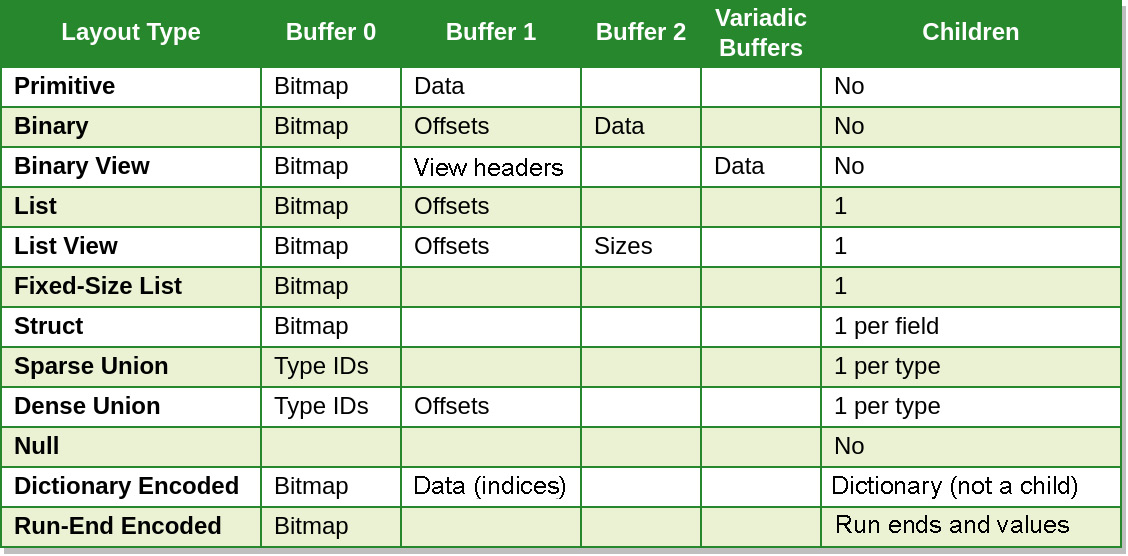
Most important physical layouts details:
- Primitive fixed-value arrays
- Variable-length binary arrays
- Variable-length binary view arrays (German Strings)
- List and fixed-sized list array
- ListView arrays
- Struct Arrays
- Union Arrays
- Run-encoded arrays
Arrow Data Types
These types are the types of an array, rather than the physical layout:
- Null type: Null physical type.
- Boolean: A primitive array with data represented as a bitmap.
- Primitive integer types: A primitive, fixed-size array layout:
- Int8, Uint8, Int16, Uint16, Int32, Uint32, Int64, and Uint64
- Floating-point types: A primitive, fixed-size array layout:
- Float16, Float32 (float), and Float64 (double)
- VarBinary types: A variable-length binary physical layout:
- Binary and String (UTF-8)
- LargeBinary and LargeString (variable-length binary with 64-bit offsets)
- VarBinary view types: Variable-length binary view physical layout:
- BinaryView and StringView (UTF-8)
- Decimal128 and Decimal256: 128-bit and 256-bit fixed-size primitive arrays with metadata to specify the precision and scale of the values.
- Fixed-size binary: A fixed-size binary physical layout.
- Temporal types: A primitive fixed-size array physical layout.
- Date types: Dates with no time information:
- Date32: 32-bit integers representing the number of days since the Unix epoch (1970-01-01)
- Date64: 64-bit integers representing milliseconds since the Unix epoch (1970-01-01)
- Time types: Time information with no date attached:
- Time32: 32-bit integers representing elapsed time since midnight as seconds or milliseconds. A unit specified by metadata.
- Time64: 64-bit integers representing elapsed time since midnight as microseconds or nanoseconds. A unit specified by metadata.
- Timestamp: A 64-bit integer representing the time since the Unix epoch, not including leap seconds. Metadata defines the unit (seconds, milliseconds, microseconds, or nanoseconds) and, optionally, a time zone as a string.
- Interval types: An absolute length of time in terms of calendar artifacts:
- YearMonth: The number of elapsed whole months as a 32-bit signed integer.
- DayTime: The number of elapsed days and milliseconds as two consecutive 4-byte signed integers (8 bytes total per value).
- MonthDayNano: The elapsed months, days, and nanoseconds stored as contiguous 16-byte blocks. Months and days are stored as two 32-bit integers and nanoseconds since midnight is a 64-bit integer.
- Duration: An absolute length of time not related to calendars as a 64-bit integer and a unit specified by metadata indicating seconds, milliseconds, microseconds, or nanoseconds.
- Date types: Dates with no time information:
- List and FixedSizeList: Their respective physical layouts:
- LargeList: A list type with 64-bit offsets.
- ListView: A variable-length list view layout.
- LargeListView: ListView with 64-bit offsets and sizes.
- Struct, DenseUnion, and SparseUnion types: Their respective physical layouts.
- Map: A data type that is physically represented as List<Struct<key: K, value: V>>, where K and V are the respective types of the keys and values in the map:
- Metadata is included indicating whether or not the keys are sorted.
- Dictionary: Physically represented with the dictionary-encoded physical layout as Dict<index: I, value: V>, where I can be any integral type and V can be any other data type.
- Run-end encoded: Physically represented using the REE<run_ends: E, values: V> run-end encoded layout, where E can be Int16, Int32, or Int64, and V can be any data type.
Arrow format versioning and stability
To ensure confidence that updating the version of the Arrow library in use won’t break applications and the long-term stability of the Arrow project, two versions are used to describe each release of the project: the format version and the library version.
Provided the major version of the format is the same between two libraries of a different version, any new library is backward-compatible with any older library with regards to being able to read data and metadata produced by an older library.
Format version updates are to be considered an exceptional event, and they haven’t happened in 4 years since the release of the 1.0 version of the Arrow format.
RecordBatch
A record batch refers to a group of equal-length arrays and a schema. Often, a record batch will be a subset of rows of a larger dataset with the same schema. Record batches are a useful unit of parallelization for operating on data, as we’ll see more in-depth in later chapters.
A RecordBatch is like a struct, and in fact it will use the struct physical layout: an array with one child array for each field of our struct. This means that to refer to the entire struct at index i, you simply get the value at index i from each of the child arrays in the same way that if you were looking at a record batch; you do the same thing to get the semantic row at index i