Embeddings are numerical representations of real-world data such as text, speech, image, or videos. They are expressed as low-dimensional vectors where the geometric distances of two vectors in the vector space is a projection of the relationships between the two real-world objects that the vectors represent.
Tip
IEmbeddings provide compact representations of data of different types, while simultaneously also allowing you to compare two different data objects and tell how similar or different they are on a numerical scale. For example, he word ‘computer’ has a similar meaning to the picture of a computer, as well as the word ’laptop’ but not to the word ‘car’.
These low-dimensional numerical representations of real-world data significantly helps efficient large-scale data processing and storage by acting as means of lossy compression of the original data while retaining its important properties.
Categorical feature embeddings
Language-model notes usually describe embeddings as vectors produced for tokens, sentences, images, or documents. Recommender systems also use trainable categorical embedding tables: one learned row for each user id, item id, board id, query id, topic id, or action id.
That table lookup is not a semantic encoder pass over the object’s content. The id selects a row, and training updates that row when examples involving the id produce prediction error. See Categorical Feature Embeddings in Recommender Systems for the lookup path and why product ids such as board ids can carry ranking signal.
Embedding and search
One of the key applications for embeddings is retrieval and recommendations, where the result is usually from a massive search space. For example, Google Search is a retrieval with the search space of the whole internet. Today’s retrieval and recommendation systems’ success depends on the following:
- Precomputing the embeddings for billions items of the search space.
- Mapping query embeddings to the same embedding space.
- Efficient computing and retrieving of the nearest neighbors of the query embeddings in the search space.
Embedding and multi-modality
Most applications work with large amounts of data of various modalities: text, speech, image, and videos to name a few.
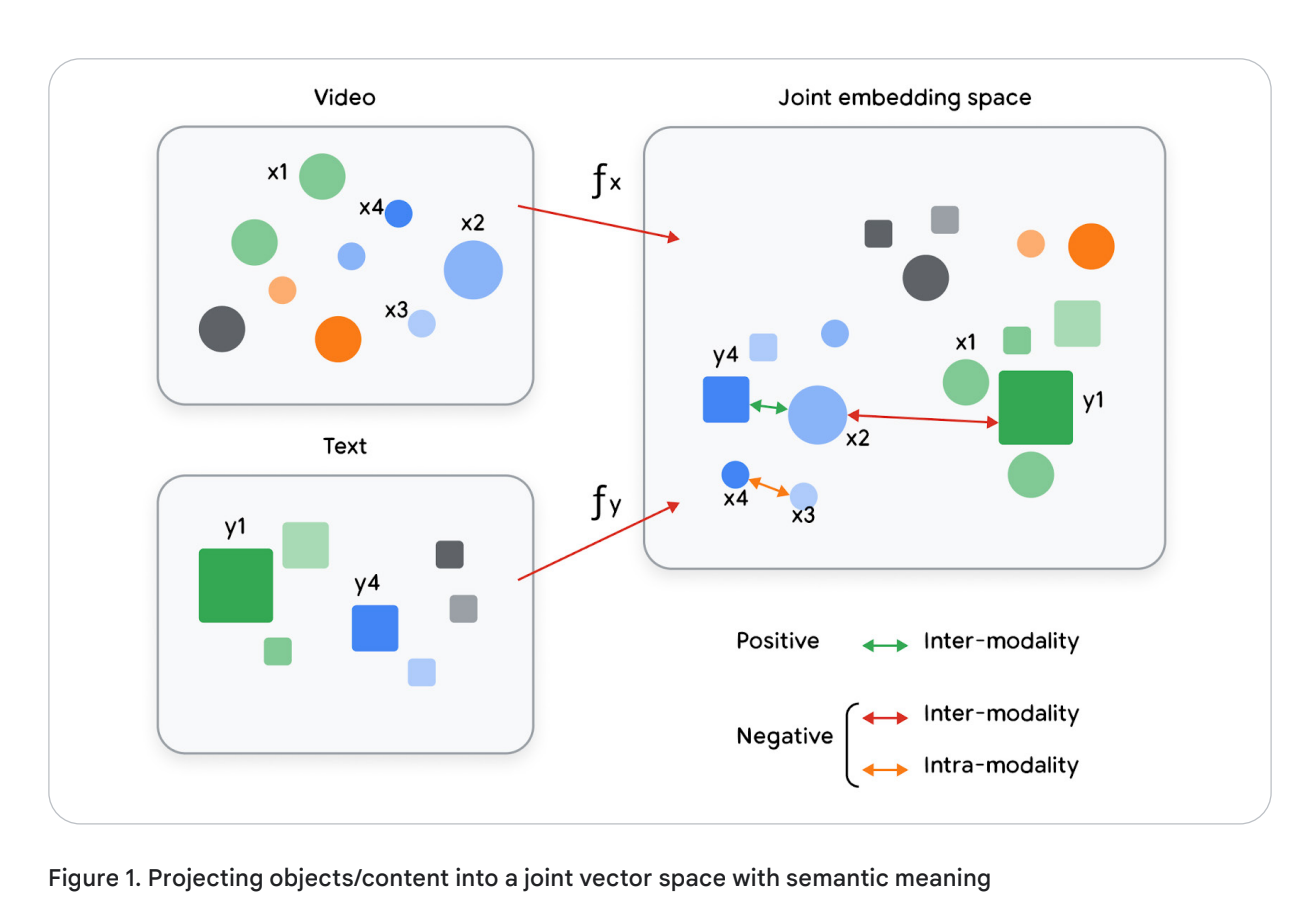
Embeddings support multi-modal use cases by placing objects with similar semantic properties close in the vector space. Furthermore, the representation can be task specific so you can generate different embeddings for the same object, optimized for the task at hand
Types of Embeddings
Text embeddings
Text embeddings are used extensively as part of natural language processing (NLP). They are often used to embed the meaning of natural language in machine learning for processing in various downstream applications such as text generation, classification, sentiment analysis, and more. These embeddings broadly fall into two categories:
- token/word
- document embeddings
The process to go from text to embeddings is the following:
- Each input string is tokenized into smaller pieces
- Each token is assigned a unique integer value, the token id, in the range [0, total token number] (indexing)
- For each input string composing the initial text, the representation can be sparse or converted to dense via one-hot encoding (1 means token is present, 0 absent)
Warning
So far, Token ID are assigned randomly so they lack inherent semantic meaning
Word embeddings
Word-embeddings or sub-word embeddings can be of two types:
- context-free: the embeddings will be the same for each word independent from the context
- context-aware: the embeddings will change on context
The most popular approaches are GloVe, SWIVEL and Word2Vec. These are models that gets trained first, tehn used to generate embeddings.
Word2Vec
Word2Vec is a family of model architectures that operates on the principle that “the semantic meaning of a word is defined by the word that appear frequently close to it”
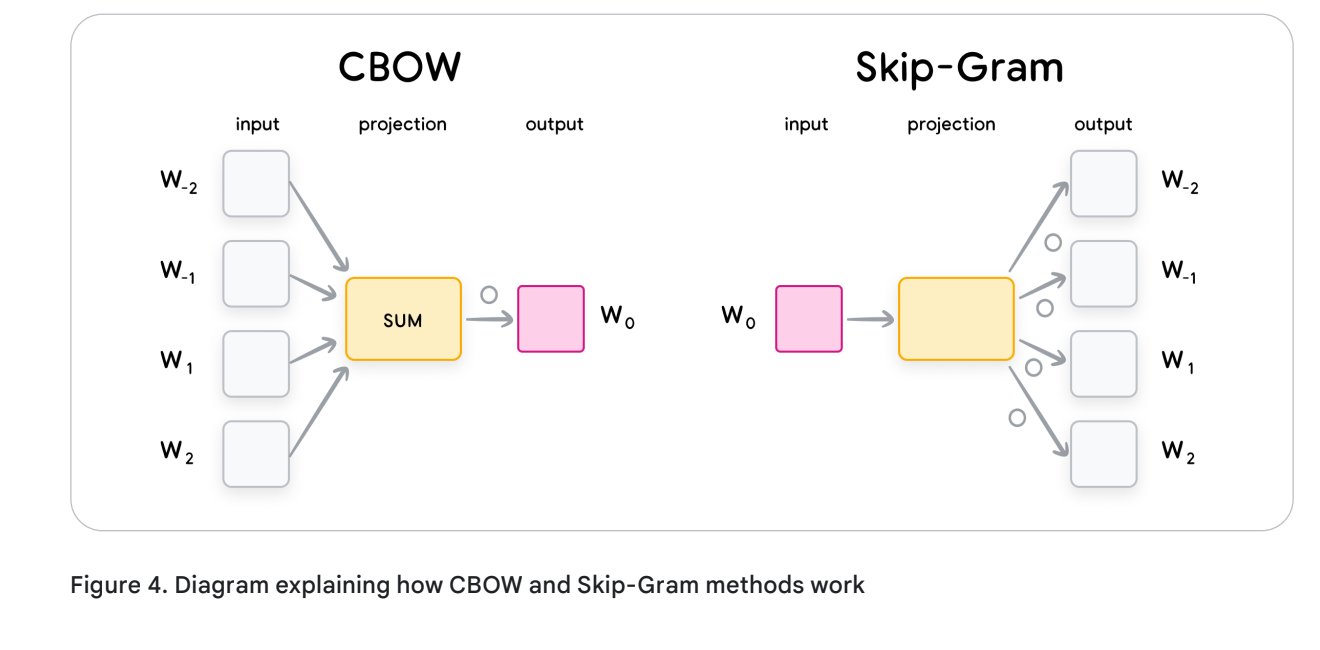
Word2Vec uses a matrix of size (size_of_vocabulary, size_of_each_embedding) where each row is the embedding for a certain entry in the vocabulary. This matrix is initialized randomly and then one of the following two training approaches are used: • The Continuous bag of words (CBOW) approach: Tries to predict the middle word, using the embeddings of the surrounding words as input. This method is agnostic to the order of the surrounding words in the context. This approach is fast to train and is slightly more accurate for frequent words. • The skip-gram approach: The setup is inverse of that of CBOW, with the middle word being used to predict the surrounding words within a certain range. This approach is slower to train but works well with small data and is more accurate for rare words.
Note
The shallow neural network can only predict for one input at the time, so how do CBOW and Skip-Gram work?
- For Skip-Gram, the output for each word is the distribution of the context, nothing to do here.
- For CBOW, we perform a prediction for each word and we sum the probabilities, then we try to maximize w0
Local statistics
Although Word2Vec accounts well for local statistics of words within a certain sliding window, it does not capture the global statistics (words in the whole corpus). This shortcoming is what methods like the GloVe algorithm address.
Tip
It is possible to train your own embeddings from scratch or re-use existing pre-trained embedding models.
GloVe and SWIVEL
GloVe is a word embedding technique that leverages both global and local statistics of words. It does this by first creating a co-occurrence matrix, which represents the relationships between words and then uses a factorization technique to learn word representations
SWIVEL is another approach which leverages the co-occurrence matrix to learn word embeddings. SWIVEL stands for Skip-Window Vectors with Negative Sampling. Unlike GloVE, it uses local windows to learn the word vectors by taking into account the co-occurrence of words within a fixed window of its neighboring words.
SWIVEL also considers unobserved co-occurrences and handles it using a special piecewise loss, boosting its performance with rare words. It is generally considered only slightly less accurate than GloVe on average, but is considerably faster to train. This is because it leverages distributed training by subdividing the Embedding vectors into smaller sub-matrices and executing matrix factorization in parallel on multiple machines.
Document embeddings
Document embeddings can be used in various applications, including semantic search, topic discovery, classification, and clustering to embed the meaning of a series of words in paragraphs and documents and use it for various downstream applications.
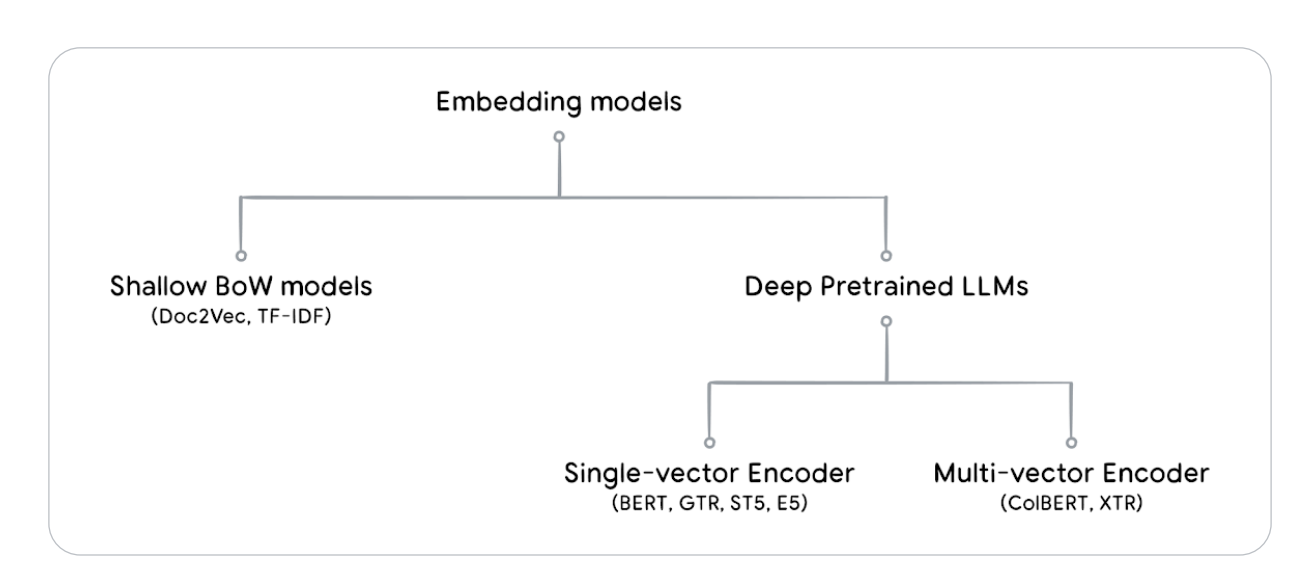
The evolution of the embedding models can be mainly categorized into two stages:
- shallow Bag-of-words (BoW) models
- deeper pretrained large language models
Shallow BoW models
Early document embedding works follow the bag-of-words (BoW) paradigm, assuming a document is an unordered collection of words. Common approaches were:
- Latent semantic analysis (LSA) that uses a co-occurrence matrix of words in documents
- Latent dirichlet allocatoin(LDA) uses a bayesian network to model document embeddings
- Term-frequency inverse document frequency(TF-IDF) that use the word frequency to represent document embedding
Warning
The bag-of-words paradigm also has two major weaknesses: both the word ordering and the semantic meanings are ignored. BoW models fail to capture the sequential relationships between words, which are crucial for understanding meaning and context.
Inspired by Word2Vec, Doc2Vec was proposed in 2014 for generating document embeddings using shallow (one or few layers) neural networks. The Doc2Vec model adds an additional ‘paragraph’ embedding or, in other words, document embedding in the model of Word2Vec.
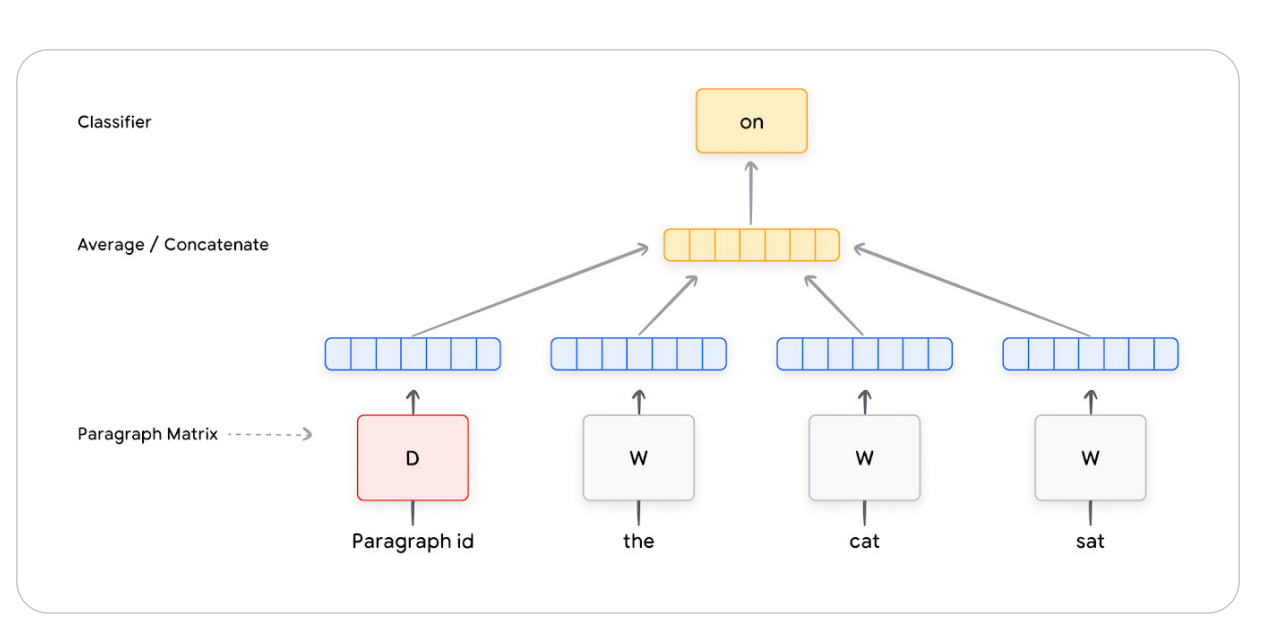
The paragraph embedding is concatenated or averaged with other word embeddings to predict a random word in the paragraph. After training, for existing paragraphs or documents, the learned embeddings can be directly used in downstream tasks. For a new paragraph or document, extra inference steps need to be performed to generate the paragraph or document embedding.
Deeper pretrained language models
The advances in deep neural network motivated creation of new embedding models:
- Powered by more complex learning models, such as bidirectional deep neural network
- Using massive pre-training unlabeled text
- Using subword tokenizer
- Using fine-tuning for various tasks
BERT
In 2018, BERT, bidirectional encoder representations from transformers was proposed with groundbreaking results on 11 NLP tasks. Transformer, the model paradigm BERT based on, has become the mainstream model paradigm until today.
Another key of BERT’s success is from pre-training with a massive unlabeled corpus. In pretraining, BERT utilizes:
- masked language model (MLM) as the pre-training objective
- next-sentence prediction The embedding of the first token (a special token named [CLS]) is used as the embedding for the whole input.
Masked language model training objective
i> Randomly masking some tokens of the input and using the masked token id as the prediction objective allows the model to utilize both the right and left context to pretrain a deep bidirectional transformer.
BERT became the base model for multiple embedding models, including Sentence- BERT,SimCSE,and E5.14 Meanwhile, the evolution of language models - especially large language models - never stops. T5 was proposed in 2019 with up to 11B parameters. PaLM was proposed in 2022 to push the large language model to a surprising 540B parameters. Models like Gemini from Google, GPT models from OpenAI and Llama models from Meta are also evolving to newer generations at astonishing speed.
- ai Understand the relationship between embeddings and LLM — see Embedding Models vs LLMs
Multi-vector Encoder models
Generating multi-vector embeddings instead of a single vector to enhance the representational power of the models. Embedding models in this family include ColBERT and XTR.
- ai understanding what are multi-vector embeddings
Image and Multimodal embeddings
Unimodal image embeddings can be derived in many ways: one of which is by training a CNN or Vision Transformer model on a large scale image classification task (for example, Imagenet), and then using the penultimate layer as the image embedding. This layer has learnt some important discriminative feature maps for the training task. It contains a set of feature maps that are discriminative for the task at hand and can be extended to other tasks as well.
To obtain multimodal embeddings you take the individual unimodal text and image embeddings and their semantic relationships learnt via another training process.
- ai understands how you get multi-modal embedding from unimodal embeddings
Structured data embeddings
There are two common ways to generate embeddings for structured data, one is more general while the other is more tailored for recommendation applications. Pre-trained embedding models are not available for structured data since they need to be specific to the application.
General structured data embeddings
Given a general structured data table, we can create embedding for each row. This can be done by the ML models in the dimensionality reduction category, such as the PCA model. Common use cases for those embeddings are:
- anomaly detection
- downstream classification
Tip
Compared to using the original high-dimensional data, using embeddings to train a supervised model requires less data. This is particularly important in cases where training data is not sufficient.
Recommendation (User/item structured data)
If the input includes the user data, item/product data plus the data describing the interaction between user and item/product, such as rating score, we can use embedding to This map two sets of data (user dataset, item/product/etc dataset) into the same embedding space.
For recommender systems, we can create embeddings out of structured data that correlate to different entities such as products, articles, etc. Again, we have to create our own embedding model. Sometimes this can be combined with unstructured embedding methods when images or text descriptions are found.
Graph Embeddings
Graph embeddings are an embedding technique that can represent not only information about a specific object but also its neighbors (namely, their graph representation).
Graph embeddings can also be used for a variety of tasks, including:
- node classification
- graph classification
- link prediction (a suggested friend in a social network)
- clustering
- search
- recommendation systems
Popular algorithms for graph embedding include DeepWalk, Node2vec, LINE, and GraphSAGE.
Training embedding models
Current embedding models usually use dual encoder (two tower) architecturre:
- for the text embedding model used in question-answering, one tower is used to encode the queries and the other tower is used to encode the documents
- for the image and text embedding model, one tower is used to encode the images and the other tower is used to encode the text.
Training is performed using a loss function of type contrastive , which takes tuples of inputs, positive_targets, optional_negative_targets and tries to bring positive targets closer and negative targets apart.
Similar to foundation model training, training of an embedding model from scratch usually includes two stages:
- pretraining (unsupervised learning)
- fine tuning (supervised learning).
Nowadays, the embedding models are usually directly initialized from foundation models such as BERT, T5, GPT, Gemini, CoCa. The fine-tuning of the embedding models can have one or more phases and the datasets can be created in various methods, including human labeling, synthetic dataset generation, model distillation, and hard negative mining.
- ai what is hard negative mining
Important
Embeddings can be used for tasks such as classification or named entity recognition by adding additional extra layers on top of the embedding model. The embedding model can either be:
- frozen (if the training dataset is small)
- trained from scratch
- fine-tuned