ORPO is a fine-tuning technique that streamlines the process of adapting LLMs to specific tasks. It addresses a limitation of the traditional two-stage approach. While SFT effectively adapts the model to a desired domain, it can inadvertently increase the probability of generating undesirable responses alongside preferred ones.
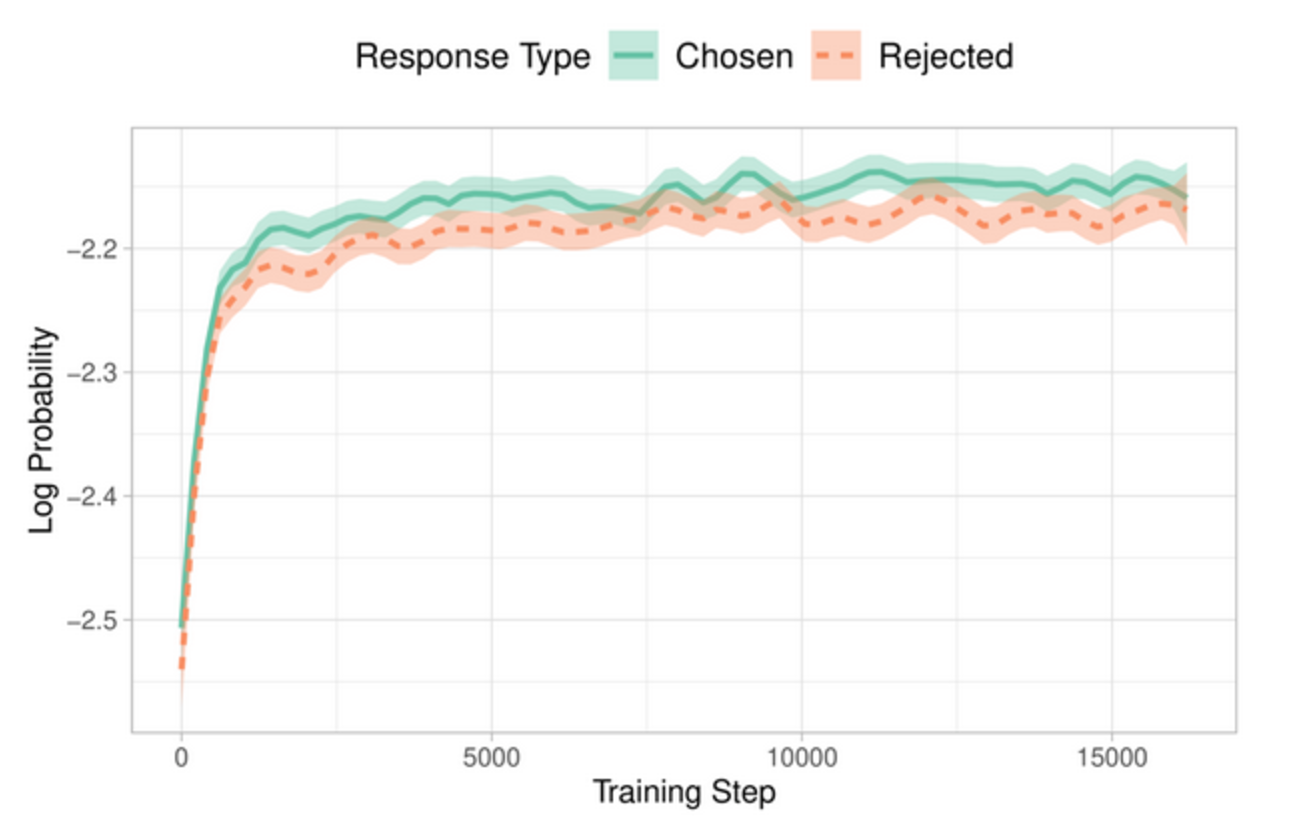 Preference alignment is employed to address this issue. It aims to:
Preference alignment is employed to address this issue. It aims to:
- Increase the likelihood of generating preferred responses.
- Decrease the likelihood of generating rejected responses. Reinforcement Learning with Human Feedback (RLHF) or Direct Preference Optimization (DPO) solves the problem using a separate reference model, increasing computational complexity, while ORPO combines SFT and preference alignment into a single objective function. It modifies the standard language modeling loss by incorporating an odds ratio (OR) term. This term:
- Weakly penalizes rejected responses.
- Strongly rewards preferred responses.
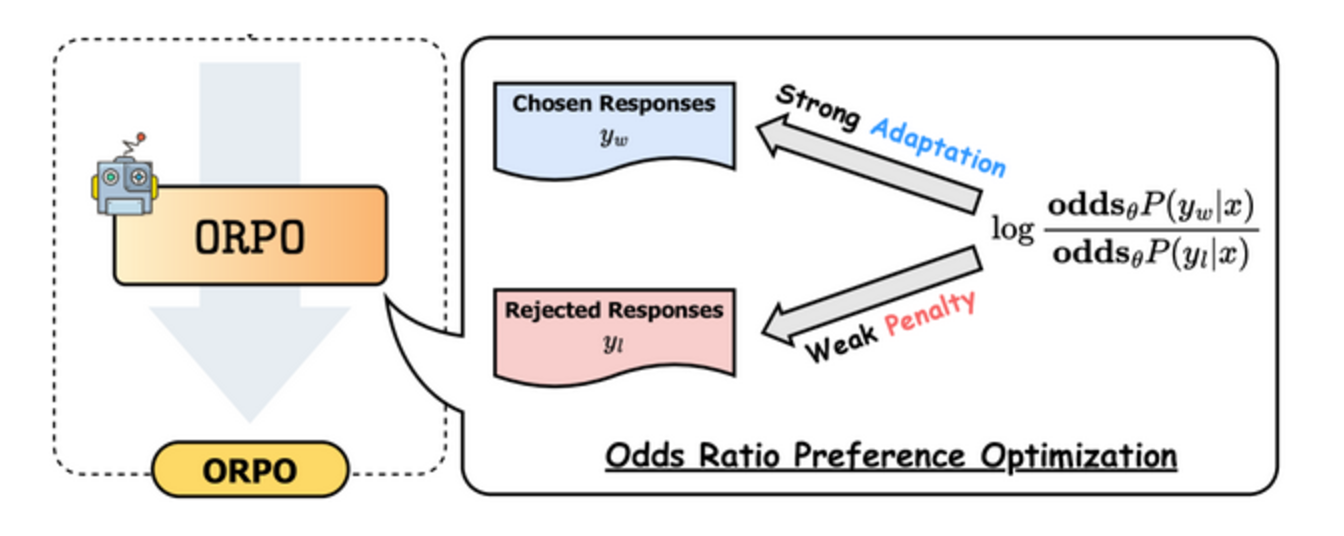 By simultaneously optimizing for both objectives, ORPO allows the LLM to learn the target task while aligning its outputs with human preferences.
By simultaneously optimizing for both objectives, ORPO allows the LLM to learn the target task while aligning its outputs with human preferences.