Numba translates Python functions to optimized machine code at runtime using the industry-standard LLVM compiler library. Numba-compiled numerical algorithms in Python can approach the speeds of C or FORTRAN.
It is designed to be used with Numpy Arrays and functions and generates specialized code for different array data types and layout. To use it one only needs to apply one of the Numba decorators to your Python function, and Numba does the rest.
from numba import njit
import random
@njit
def monte_carlo_pi(nsamples):
acc = 0
for i in range(nsamples):
x = random.random()
y = random.random()
if (x ** 2 + y ** 2) < 1.0:
acc += 1
return 4.0 * acc / nsamplesNumba also works great with Jupyter notebooks for interactive computing, and with distributed execution frameworks, like Dask and Spark. It supports
- SIMD Vectorization
- GPU Accelleration
- Simplified threading
@njit(parallel=True)
def logistic_regression(Y, X, w, iterations):
for i in range(iterations):
w -= np.dot(((1.0 /
(1.0 + np.exp(-Y * np.dot(X, w)))
- 1.0) * Y), X)
return wGPU acceleration
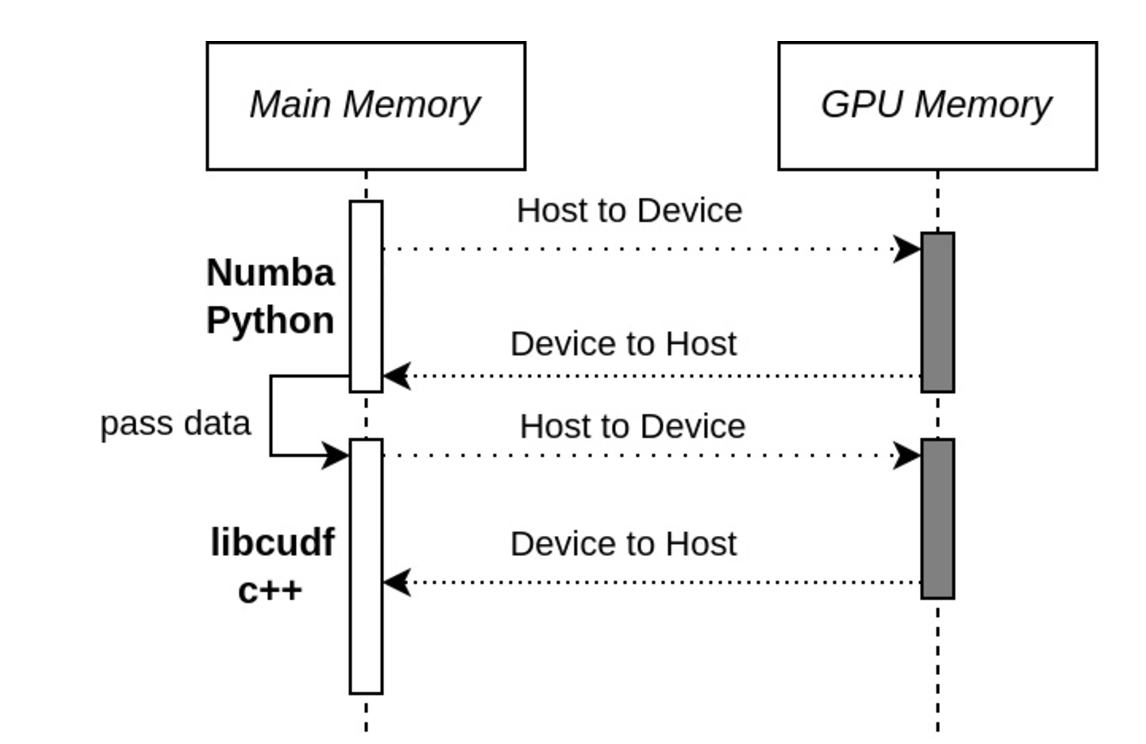
Numba GPU acceleration works in the following way:
- data is copied to the GPU from main memory using Libcudf++ under the hood
- Numba coordinates operations GPU on data by either executing high level operations using Libcudf++ or by compiling your Python Code into custom GPU Kernels
- Numba interacts directly with the CUDA APIs for Kernel execution, memory managemnet, and computation
- Results are copied back to the CPU using libcudf++
Note that libcudf++ will use Arrow format on the GPU