Researcher at the Technical University of Munich wrote a a paper that describes a system called UmbraDB, in which they outline a new-highly efficient in memory-string representation for columnar data. This representation has also been popularly named German-style strings and was later adopted by two extremely popular open source projects: Meta’s Velox engine and DuckDB. Finally, it was adapted as a data type for Arrow arrays, both to maintain zero-copy compatibility with these systems and to bring this representation to the entire ecosystem that relies on Arrow.
In this approach, the memory layout is composed of a variable number of buffers:
- as usual, the first buffer is the validity bitmap
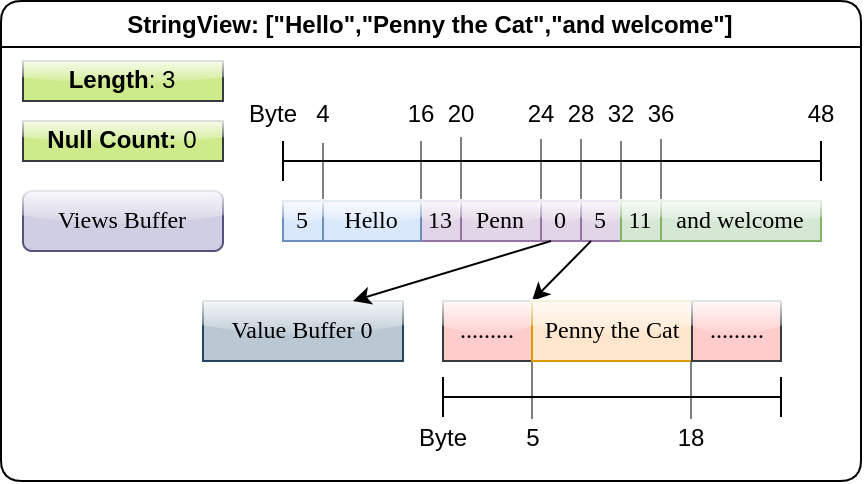
- the second buffer use a 16-byte structure to represent the location and length of each view of bytes (called a view header).
- the other buffers contain the binary data that’s too big to fit in the 16-bytes
In practice what happens is a short/small string optimization: for strings that are small enough, we store them inline in the view header, without requiring additional indirection. For larger string, we store a prefix we can use for some operations (prefix match) so we don’t need to look into the full screen if the prefix don’t match.
![]()
For example, the following array: ["Hello", "Penny the cat", "and welcome"] could be stored like in the following image:
How many data buffers?
There can be any number of data buffers, so this is only one possible representation
Key benefits of German Strings
- The fact that the strings are fixed-length mean each item can be produced in parallel without the risk of overwriting in the second buffer (the view header buffer) locations that belong to other strings
- Some operations are much faster on fixed-length value arrays (if all fits in 16 bytes, you can use SIMD)